20: Important -Financial- Decision Maker — Part Two
In part one, I came out with the idea of building a simple training model for making important financial decision. Later I rejected my own idea, because we can’t make financial related decision purely using data, and disregard emotional factors, which actually play much higher weight in the decision making process.
After all, human should not rely on machine to tell them what to do. Human should learn from their own mistakes by doing it.
I learn that from Simpsons
This episode is about Lisa and a group of female programmers building an application that tells the user if it is appropriate to post the thing to social network the moment the user tries to post. In the end, the robot convinces Lisa he is real and he is under too much stress to tell people if they should post or not, because most people are trying to post stupid things, which has the obvious answer without even the need of consulting a robot.
I wasted too much time on watching Simpsons, but surprisingly learned a few interesting life lessons. This is one of them.
What about Crowd Sourcing Decision Making?
Crowd sourcing to make decision is not really new.
Recommendation can be seen as one of the designs. However, it is easy to recommend similar items to buy, or restaurant to go, or place to visit, because they are largely supported by data with high probability. More importantly, recommendation has no responsibility to take.
Financial decision making is different. The difference is basically:
do I buy a car, v.s. which car should I buy?
A decision like this involves emotion and rationale, which cannot be calculated (accurately) by machine.
In fact, someone has already asked if such a thing exists.
Surely, there are some products out there:
- https://www.transparentchoice.com/ahp-templates
- http://www.igottaask.com/
- http://www.decisioncrowd.com
All very different. If you look at the transparentchoice, which has an example of buying a car. It looks like it’s trying to buy car 1 or car 2. Anyway, it’s fairly complicated and not easy to understand.
How will I design it?
First, ignore how practical the idea is. How will I decide it?
Since it is a crowdsourcing site, it should have the design that encourages strangers to engage. This is generally done by materially (incentives) or morally (social class). Giving out incentive is probably not possible, neither is the other option, as we are not starting from Facebook or Twitter. One technique people use is empathy/sympathy, which is basically putting visitors in the same shoes of the person who asks the question, thereby motivating the visitors to complete the request, since he or she feels it’s like doing his/her own favor.
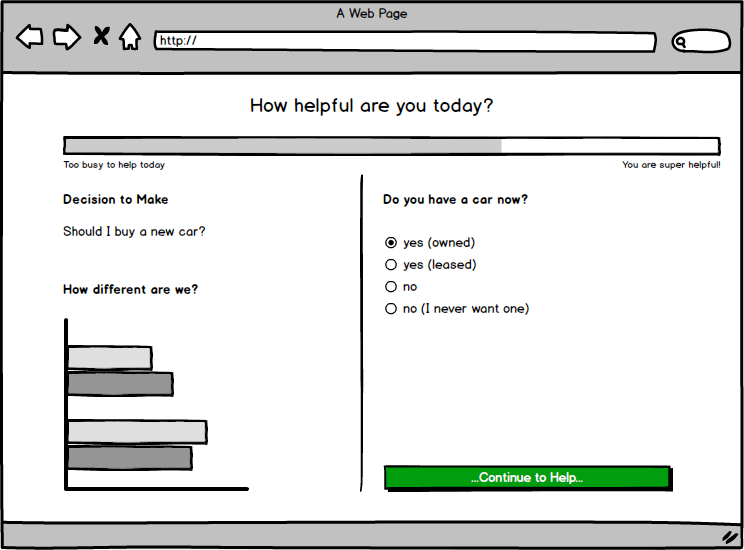
With a quick sketch, I came out with the above design.
- the visitor immediately enters a decision making procedure (omit the landing page)
- the visitor is presented as a single question: being helpful
- the visitor can see how similar himself or herself is, compared to the requester
- the visitor can see helpfulness points progression
One part of the page (the green button) will continue asking questions based on the previous answer. Those questions are provided by the requester, or suggested by some machine learning.
In this flow, the visitor never needs to answer YES or NO to the real question, because that will defeat the purpose of learning and crowd sourcing the decision making. Therefore, on the second thought, maybe the web page should hide the real question, which is “Should I buy a car?”.
Maybe the landing page that leads to this procedure will be based on proximity or ages, which makes the visitors feel closer to the requester.
In the end, the visitor will gain the helpfulness points (as an incentive), which varies by the number of questions he or she has answered.
Will it work?
Slowly, this website will accumulate people who have answered many questions and gathered the answer data for groups, like people who live in similar areas, same genders, same age group, work profession, etc.
This will help us to build a data set helps the decision making.
But, there is still no emotion or rationale factor.
Is it though?
This is actually a fantastic human study topic. God, I miss grad school when I can just came out with a hypothesis and start doing a user experiment.
The difference is how we gather the data.
In part one, I was initially thinking about hard data, which are numbers related to financial situation: income, assets, debts, etc. Those will work, but they are too naive for decision making.
In the approach I just outlined, it’s based on similarity of the requester and the helper. And the question is never about hard number (or maybe we should still weight those in, depends). For example, questions to ask in the decision “Should I buy a car” can be:
- Do you have a car already?
- Is your car working?
- Are you comfortable with additional cost each month, or just pay a big lump sum now?
- Is it stupid to buy a second car but don’t drive too much?
You see, those are soft data.
If I need a crowd sourcing decision making, I will not care the opinion from a retiree who lives in Texas and has a farm that raise horses as hobby. That is very specific. I will be more interested in the opinions from people who are 25 years old (ssssssssshhhh), live in the same area as me, as well as working in the same profession.
Therefore, I think it will probably work.
I dibs this idea: a crowd sourcing website for decision making that is based on similarity of the crowds.